GaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting
Abstract
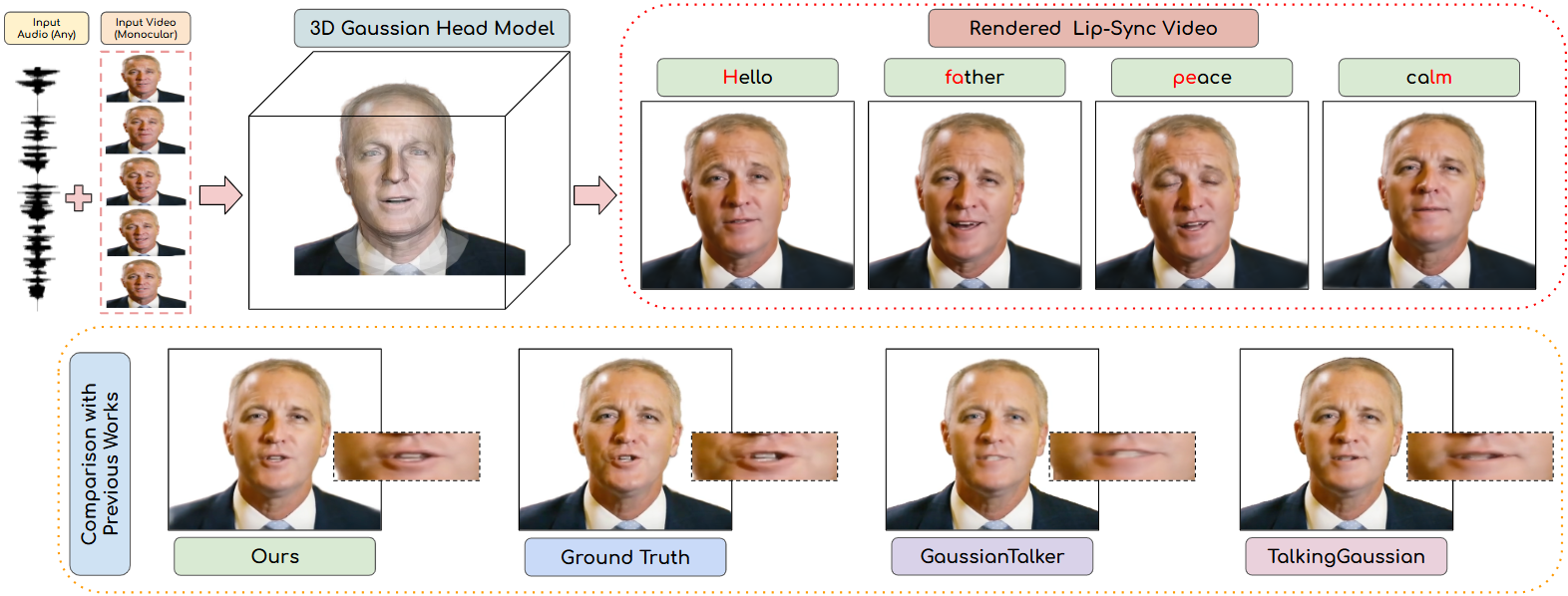
Speech-driven talking heads have recently emerged and enable interactive avatars. However, real-world applications are limited, as current methods achieve high visual fidelity but slow or fast yet temporally unstable. Diffusion methods provide realistic image generation, yet struggle with one-shot settings. Gaussian Splatting approaches are real-time, yet inaccuracies in facial tracking, or inconsistent Gaussian mappings, lead to unstable outputs and video artifacts that are detrimental to realistic use cases. We address this problem by mapping Gaussian Splatting using 3D Morphable Models to generate person-specific avatars. We introduce transformer-based prediction of model parameters, directly from audio, to drive temporal consistency. From monocular video and independent audio speech inputs, our method enables generation of real-time talking head videos where we report competitive quantitative and qualitative performance.
Demo Video
Citation
If you find this work useful for your research, please consider citing:
@InProceedings{Agarwal_2026_WACV,
author={Agarwal, Madhav and Zhang, Mingtian and Sevilla-Lara, Laura and McDonagh, Steven},
title={GaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month={March},
year={2026},
pages={8017-8027}
}